1. 용어 및 개념 정리
1) Comfy UI의 노드 시스템(Video to Video 기준)
- 블렌더의 지오메트리 노드, 터치 디자이너, 후디니, 유니티의 VFX 노드와 유사하고 데이터가 연결되어 흐름을 형성하며, 통합된 작업 흐름을 만듦
- 크게 Input / Base / AnimateDiff / IPAdapter / ControlNet/ Render / Upscale&FrameRate Interpolation 의 그룹으로 묶임
- 같은 색상의 소켓끼리 연결 (데이터의 형태가 같도록
- 커스텀 가능 (색상, 형태, 제목 등 수정가능)
- 추가 (마우스 클릭 두번하여 검색 / 오른쪽 마우스 클릭하여 선택지로 이동)
- 노드들을 Group 안에 정리 가능
- Queue Prompt 버튼을 통해 생성 시작

Group 1) Input

Load Video
- 블렌더의 렌더 아웃풋을 인풋으로 넣어주기
- 작업의 베이스가 될 영상
- 최소 fps(ex.12fps), 최소 화질로 시작해 워크플로우 마지막 마트에서 프레임 인터폴레이션(프레임 속도 빠르게) / 화질 업스케일링이 가능
- 스테이블 디퓨전 모델별로 특화된 해상도를 사용하면 생성에 유리

- Load Video(Path) 노드는 Load Video (Upload) 노드와 달리 해당 영상의 경로를 입력하면 워크플로우에 로드됨
Seed
- 생성 Queue의 Seed 역할
- Seed가 달라지면 완전히 다른 결과가 나옴
- Randomize Each Time / New Fixed Random이 있음
- Randomize를 통해 매번 다르게 생성할지 / Fixed를 통해 사용했던 버전 그대로 수정할지를 주의해야 함
VAE(변분 오토인코더, Variational AutoEncoder)
- 인풋 비디오가 Stable Diffusion이 이해할 수 있는 형태로 바뀌어야 하는데 그것이 Latent(잠재 데이터)가 있는 VAE Encode
- 입력 데이터를 잠재 공간(latent space)으로 압축하고, 다시 이를 사용해 원래의 데이터를 복원하는 구조를 지님
- Vae Encode : 인풋 비디오의 픽셀값을 잠재 데이터 (latent) 로 압축, 변환
- Vae Decode : latent 를 다시 이미지로 복원
Reroute
- 노드 흐름 연결(확장)
- 복잡해진 워크플로우를 정리하고 연결하는 데에 용이
Group 2) Base

LCM LoRA
- 생성 속도를 빠르게 해주는 LoRA
사용 조건
1. LCM LoRA와 AnimateDiff의 모델을 Animate LCM으로 설정
2. K Sampler의 step 수를 현저히 낮춰도 됨(20 아래)
3. K Sampler의 cfg : 1.0 ~ 2.0
4. K Sampler의 sampler : LCM
CR VAE Input Swith
- 필수는 아님
- CR VAE Input Switch는 VAE의 사용 여부를 선택하는 기능
- 체크포인트에 VAE가 포함된 모델이 여러 개 있어 없는 모델은 로드된 VAE 모델을 가져오고 이를 통해 VAE 1번이나 2번을 선택할 수 있음
Clip
- 텍스트 / 이미지 등을 이해하기 위한 모델
- CLIP Text : Positive, Negative 프롬프트 등의 텍스트를 이해하여 변환
- CLIP Vision : 이미지를 이해하여 변환(IPAdapter)
Group 3) AnimateDiff
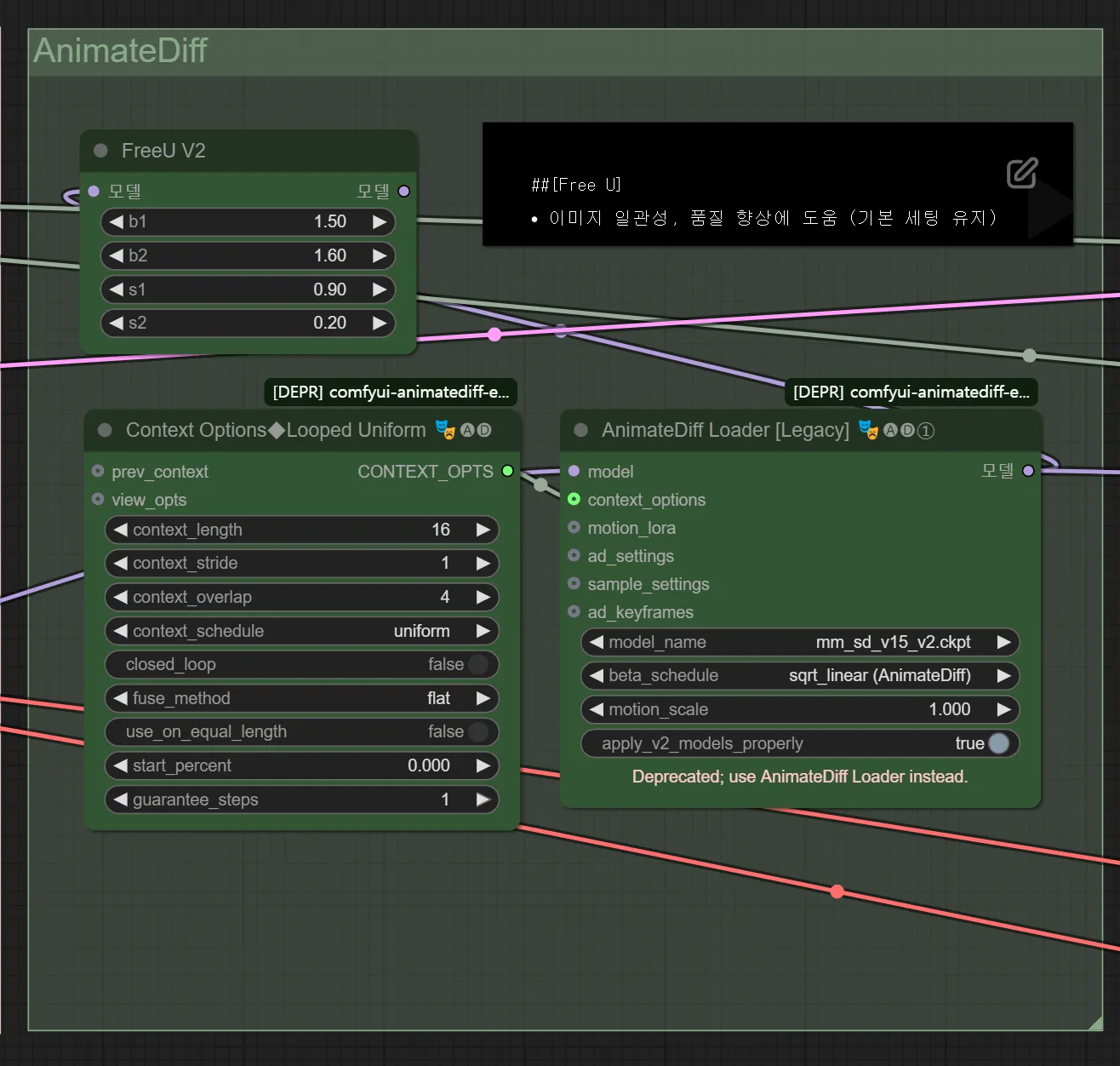
- 애니메이션 모션을 생성할 수 있도록 도와주는 역할
- Text / Image to Video 생성에 필요한 모델
- Context(맥략) : 일관성을 유지하기 위한 설정. 앞 뒤 프레임에 대한 맥락을 이해해야 모션을 이어줄 수 있음
- FreeU, Context Option은 앞 뒤의 일관성이나 자연스러운 프레임의 연결 등을 도와주는 장치
- Motion Module(mm) : 연속된 프레임 간 자연스러운 동작 연결을 생성하기 위한 장치
- LCM LoRA 사용 시에는 AnimateDiff 모델을 Animate LCM으로 설정
Group 4) IP-Adapter
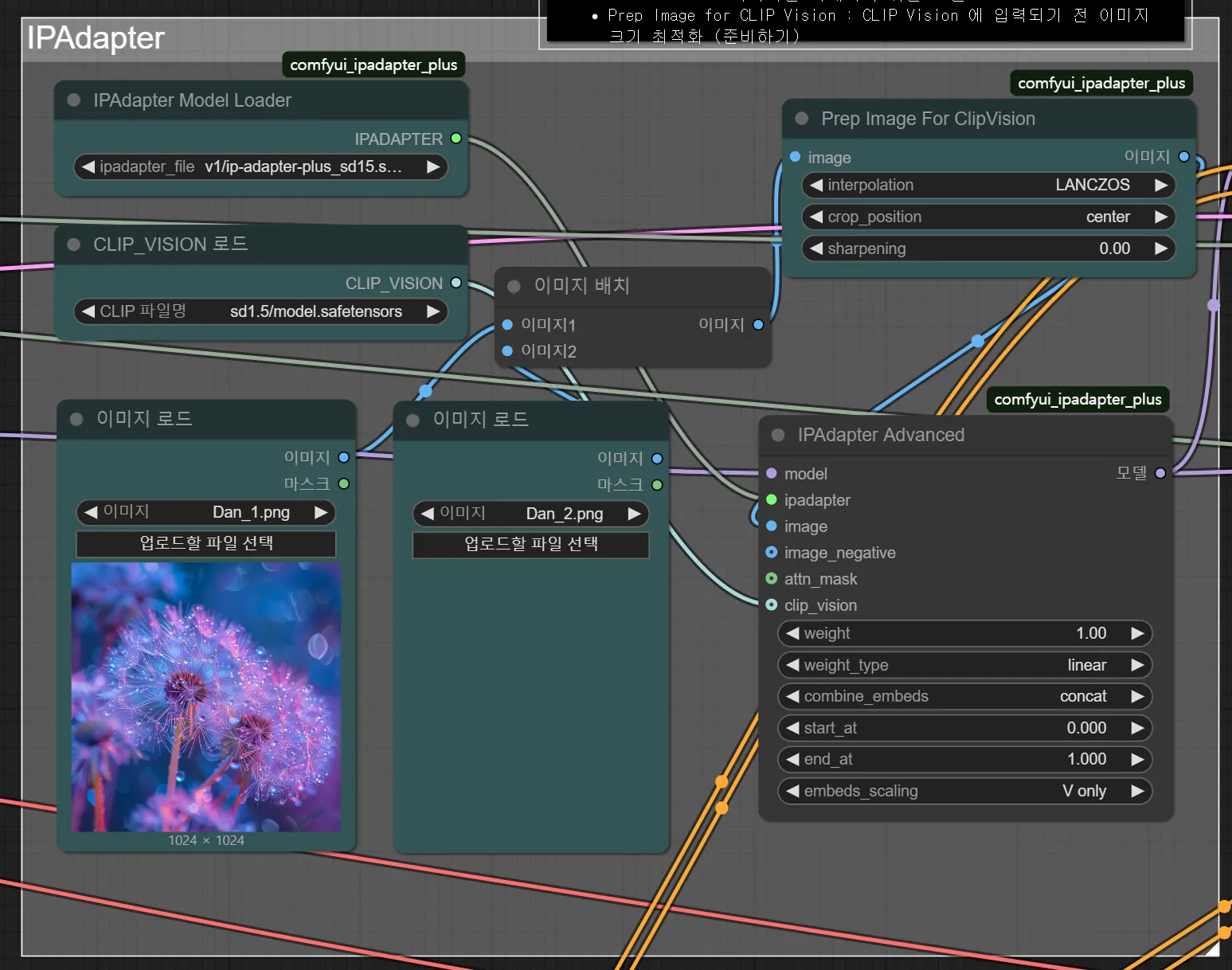
- Iamge Prompt Adapter : 이미지를 프롬프트로 사용하도록 하는 모델
- IPAdapter Model Loder : 모델 업로드
- CLIP Vision : 이미지를 이해하기 위한 모델 'Vision'
- Prep Image for CLIP Vision : CLIP Vision에 입력되기 전 이미지 크기 최적화(준비하기)
만약 ComfyUI 폴더 내의 IPA-dapter 폴더에 저장 시 (\Data\Packages\ComfyUI\models\ipadapter) 적용이 되지 않는다면, \Data\Models 폴더 내에 'Ipadpater' 폴더를 만들어 저장할 것
Group 5) ControlNet

- 원본 이미지의 특정 내용을 감지하여 반영
- 선, 깊이감, 면, 포즈 등 다양한 포인트를 인식
- 작업 내용에 따라 서로 다른 ControlNet을 선택하여 적용
- strength 조정 가능
- start percent : 해당 controlNet의 반영이 시작되는 시점 (0.0일 경우 처음부터 모두 반영)
- end percent : 해당 controlNet의 반영이 끝나는 시점 (1.0일 경우 끝까지 모두 반영)
Control GIF
- QRCode Monster라는 모델은 예상치 못하는 흐름을 가져다 줌
Group 6) Render

K Sampler
- 렌더의 역할을 함
- Model : Checkpoint, LoRA, AnimateDiff, IPAdapter 등을 거쳐 온 보라색 노드를 연결
- Positive : positive CLIP, Prompt, ControlNet 등 노란색 노드를 연결
- Negative : negative CLIP, Prompt, ControlNet 등 노란색 노드를 연결
- Latent Image : VAE Encode를 거쳐 나온 Latent 또는 Empty Latent Image의 Latent 등을 연결
- Steps : 몇 번의 연산 과정을 거칠 지(LCM LoRA를 사용한는 것이 아니라면 최소 24)
- cfg : 생성 과정 중 프롬프트 등의 조건을 얼마나 반영 할 지 (8.0~12.0 혹은 LCM LoRA를 사용할 경우 1.0~2.0 권장)
- cfg가 높을수록 입력 조건 충실히 반영(너무 높을 경우 왜곡됨)
- Scheduler : 샘플링 연산의 종류
- Denoise : Noise 비율을 얼마나 줄 것인가(denoise가 높을수록 원본에서 벗어남)
Video Combine
- 생성된 이미지들을 모아서 영상 생성
- fps, 영상 포맷(gif, mp4 등) 설정 가능
- Loop count : 반복되는 횟수
- Save metadata : 해당 영상에 메타데이터 첨부(워크플로우 설정에 대한 정보) → 정보가 새지 않았으면 좋겠다면 false로 설정
Group 7) Upscale & FrameRate Interpolation

Upscale
- Upscale Latent : 원하는 해상도의 업스케일 latent 설정(2배)
- Upscale Latent By : 'scale_by(확대율)'를 통해 몇 배로 업스케일 할 지 설정
- Upscale_method : 업스케일 연산 방법
VFI
- Video Frame Interpolation : 영상 보간(인터폴레이션)
- multiplier를 통해 프레임 간의 움직임을 부드럽게 N배 설정
- Render의 Video Combine에서 frame rate가 12였던 것을 multiplier 2로 설정하니 마지막 Video Combine에서는 frame rate를 24로 해줄 수 있음
Export PNG
- 오른쪽 마우스 클릭하여 Workflow Image 설정 -> 워크플로우를 svg / png 파일로 추출
- 데이터를 임베드할 시 이미지 자체에 워크플로우를 저장 (save metadata 와 비슷하게 적용됨)
- save_metadata가 true로 설정되어 모든 워크플로우에 대한 정보가 담긴 영상 및 이미지를 갖고 있어도 워크플로우가 불러와짐
'2. 3D 렌더링 및 생성형 AI 공부 > Stable Diffusion & Blender' 카테고리의 다른 글
| 1. [Stable Diffusion] Blender & Stable Diffusion 이해 (2) | 2025.03.26 |
|---|