1. 배경 지식
1) 3D툴과 AI의 현 주소
AI와 3D 기술 발전의 배경
- 3D 공간을 작은 Gaussian 블롭(구름 같은 작은 덩어리)으로 표현해 3D와 AI 분야에서 유망하게 손꼽히는 기술 → 가우시안 스플래팅 기법
- 엔비디아의 Get 3D
- 빅 테크기업들은 자사를 위한 인공지능 모델들을 학습시키고 있음
흥미로운 툴들
| Luma AI | Zibra AI | Spline AI |
|
|
|
2) Blender 소개
- 오픈소스이자 비영리 커뮤니티에서 만든 3D 소프트웨어로 모델링, 애니메이션, 렌더링, 시뮬레이션 등 다양한 기능을 제공
- 굉장히 많은 커뮤니티, 개발자와 기술 관련 커뮤니티 접점이 많아 기술이 발전이 높음
- 노드 베이스의 기능들도 많이 나오고 파이썬 스크립팅도 가능
- GPU 렌더러를 적극 지원한다는 것 → AI 파워를 적극 활용을 암시
- AI 모델 학습 환경에서 굉장히 촉망 받는 파일 포맷인 OpenUSD를 지원하는 면들을 보면 AI 관련 산업과 긴밀한 관계임을 유추 가능
3) Stable Diffusion 소개
개발자가 아닌 크리에이터들은 대체 어디서 모델을 구하고 어떻게 팔로우 업을 하면서 펼쳐놓고 써야할까?
- Stability AI에서 만든 텍스트 투 이미지 모델 → 오픈소스로 공유되어 있음
CIVIT AI
- 작업하는 환경에서 필요한 모델들을 리서치하고 다운 받아서 워크플로우에 적용
- 강점은 자신이 가지고 있는 이미지들을 학습시켜 나만의 모델을 만들 수 있음
OpenArt AI
- Compy UI에 대한 리소스가 굉장히 많음
- 워크플로우에 대한 도움을 받음
- 이미 셋팅된 프로세스가 있어 원하는 기능들을 시험 가능함 → Outpainting, Upscale 등
4) Comfy UI 소개
- Stable diffusion의 팔레트 역할을 하는, 워크플로우를 펼쳐놓고 볼 수 있도록 해주는 UI인 Compy UI
- 가장 전형적인 UI인 Automatic1111 Web UI. 그 외에 Fooocus, Kohya SS, SD.Next, Invoke Ai Compy UI 등이 있음

- Compy UI가 다양한 크리에이터에게 사랑 받는 이유는 워크플로우를 노드의 형식으로 한 눈에 볼 수 있음. 더 다양하고 고급화된 워크플로우를 제작할 수 있음

2. 작업환경 셋팅
1) Stability matrix
Stable Diffusion
- 오픈소스 라이선스로 배포된 이미지 생성 및 변환을 위한 딥러닝 기반의 생성형 모델. 특히 텍스트 설명을 바탕으로 고품질 이미지를 생성하는 데에 사용
Stability Matrix
- Stable Diffusion을 위해 설계된 멀티 플랫폼 패키지 관리자. 멀티 플랫포에서 관리하고 배포하는 방식으로, 통합된 관리 도구를 사용. 필요한 라이브러리와 모델 파일을 수동으로 다운로드하고 설정하지 않아도 됨
- CPU 8코어 이상, GPU Nvidia RTX 3070이상, RAM 32GB이상, VRAM 8GB이상, 필요한 모델 및 프로그램 모두 본인 PC에 설치
2) Blender
- 주로 Import하는 파일 포맷은 아래와 같음
- FBX : 복잡한 3D 모델과 애니메이션을 저장하며 다양한 소프트웨어와 호환되는 포맷
- GLTF : 웹과 모바일에서 빠르게 로딩되고 렌더링할 수 있는 경량 3D 모델 포맷
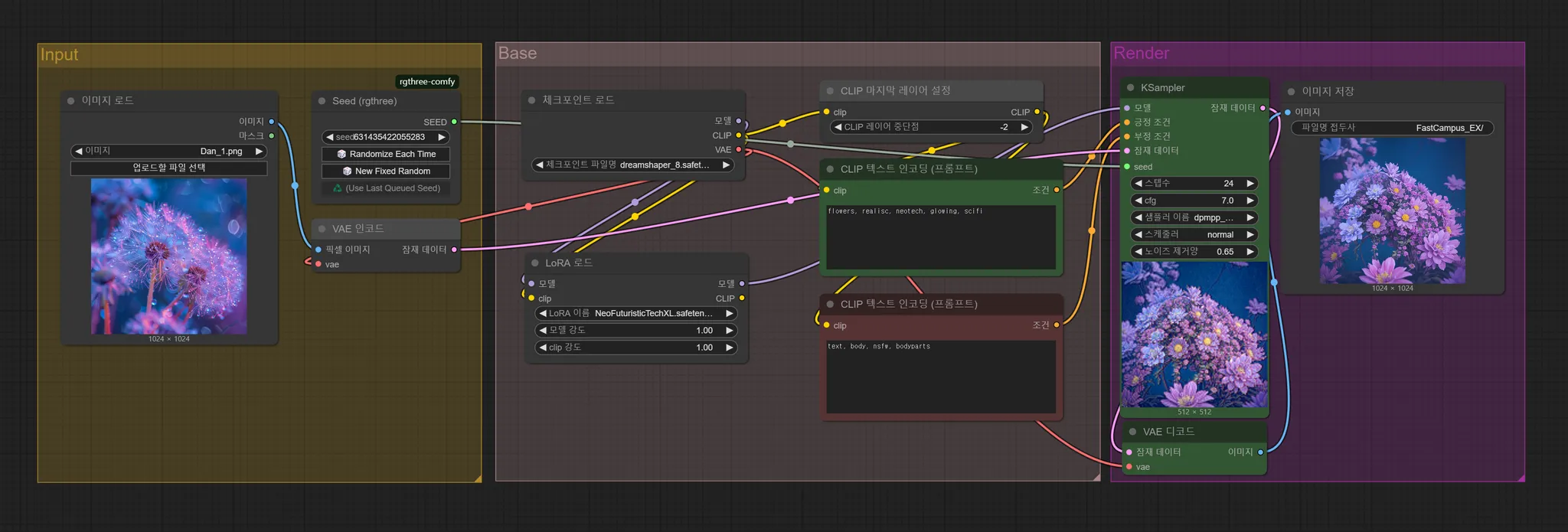
3) Stable Diffusion 기본 구조
마음에 드는 아웃풋을 위해서는 인풋 영상에 어울릴만한 프롬프팅과 그에 맞는 체크포인트, 디노이즈 값 등의 정도 등이 굉장히 잘 맞아 떨어져야 함
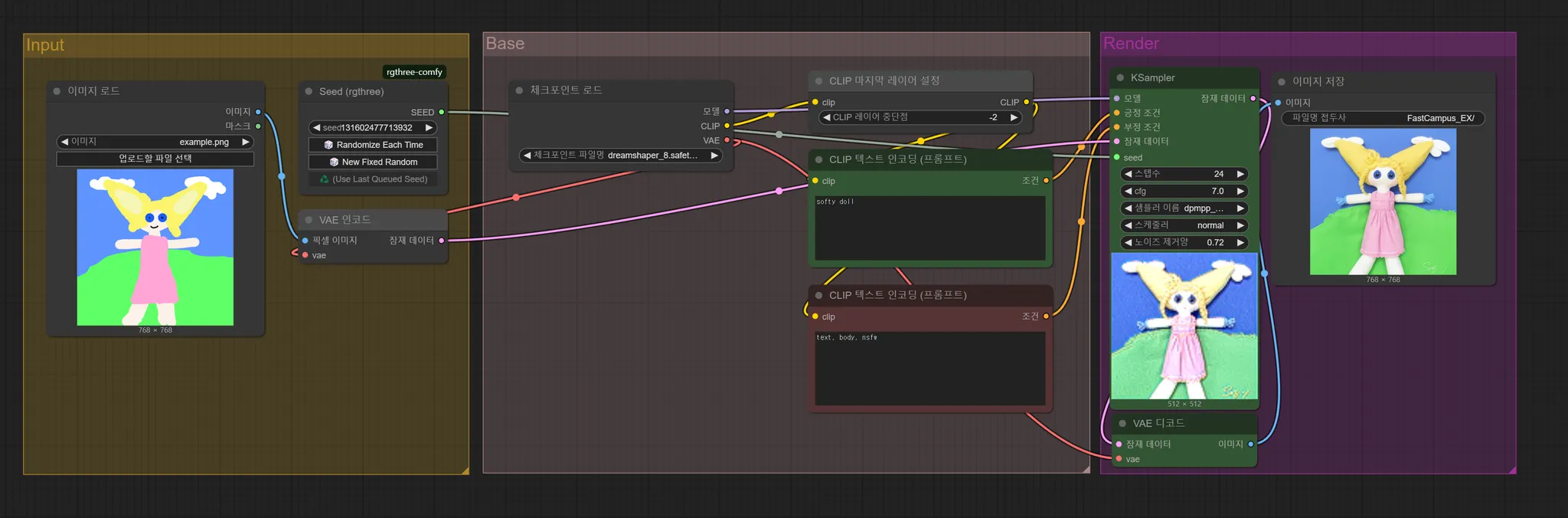
Iamge to Image 워크플로우
- 대략적인 워크플로우는 인풋 이미지 → 일련의 베이스 작업 → 렌더 아웃풋
- 베이스 : 기본적인 튜닝. 머리의 역할을 하는 체크포인트를 올리고 프롬프팅 진행
- Positive Prompting : 이미지가 따라야할 내용들에 대한 프롬프팅
- Negative Prompting : 이미지가 제외시켜야 할 것이나 따르지 않았으면 하는 것
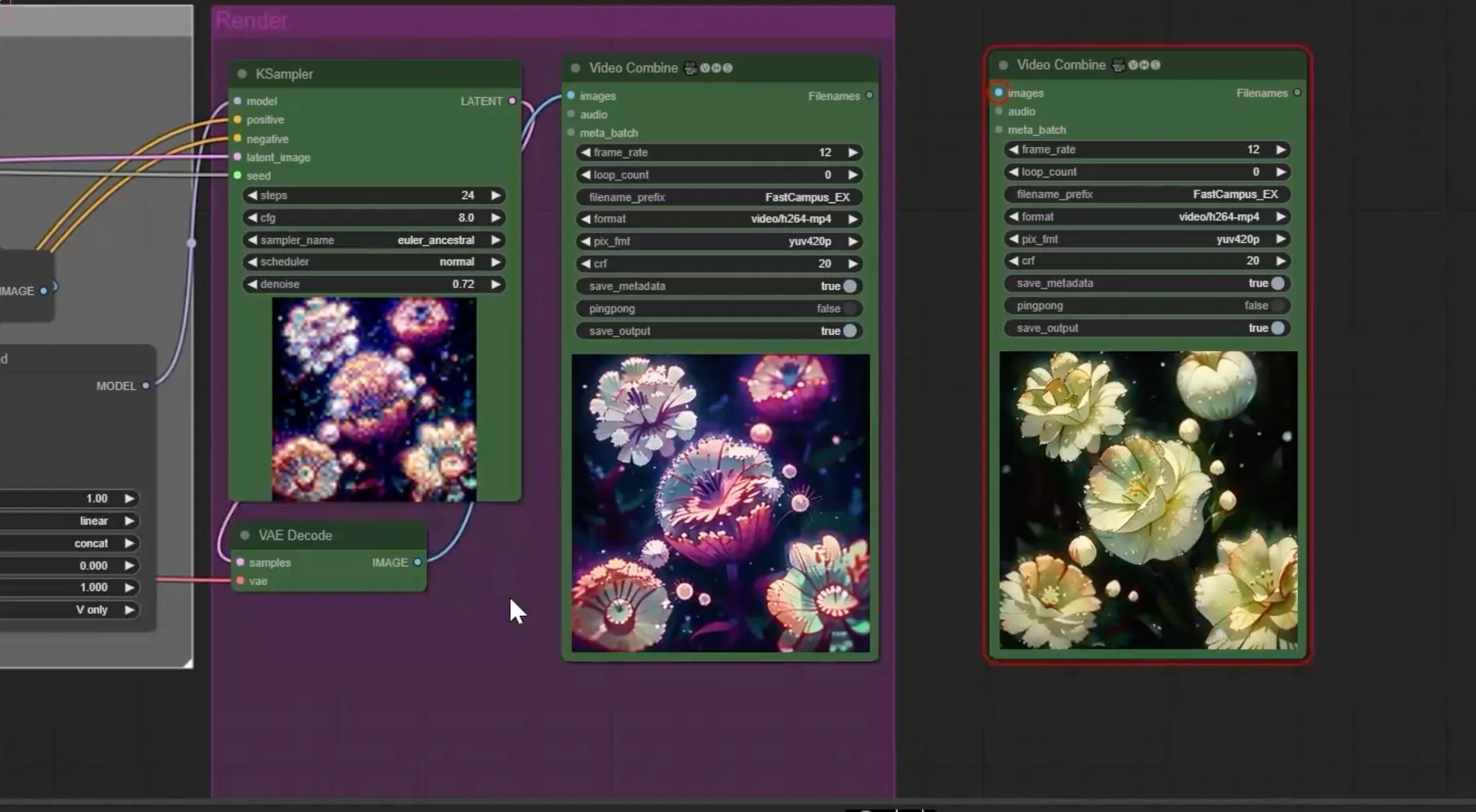
- 위의 것들을 반영해 K-sampler를 지나쳐 최종 아웃풋을 냄
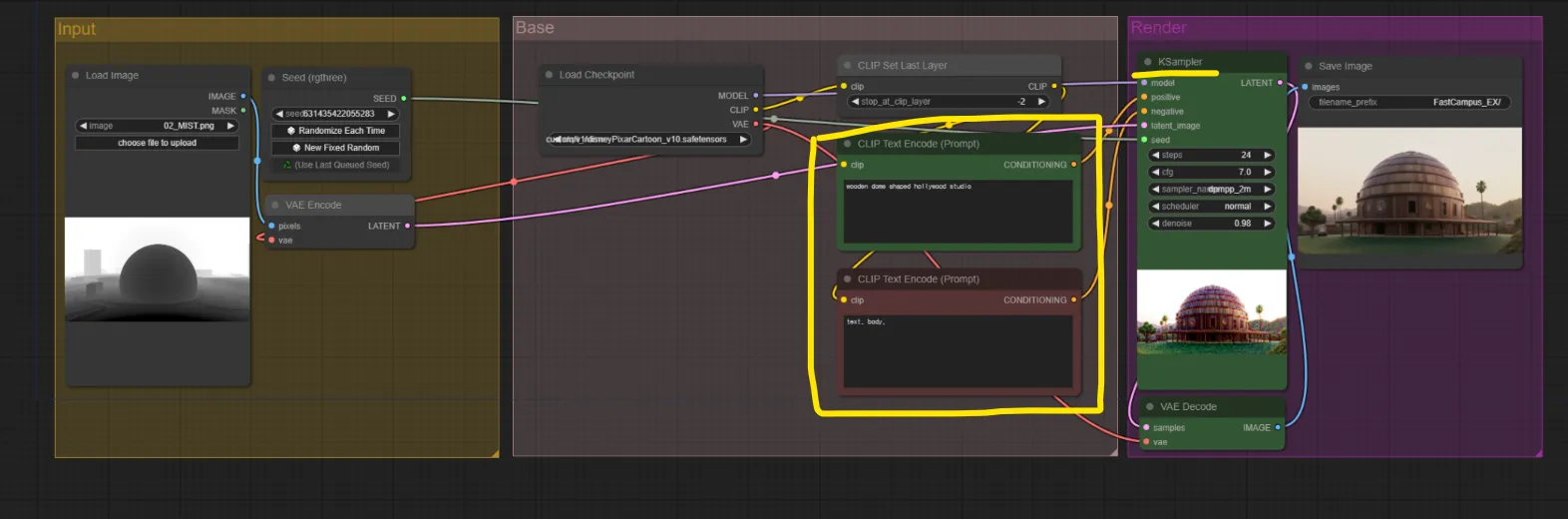
K-sampler
- 스텝수(Steps) : 그림을 그려내는 스텝의 수(디테일의 정도). 24~32정도가 적당
- cfg : 이미지를 생성할 때 입력했던 프롬프트나 이미지가 얼마나 영향을 미치는 지에 대한 것. 높을수록 명령한 것에 대해 더 가까이 가게 됨
- 노이즈 제거 양(Denoise) : 인풋으로 들어온 이미지를 어느정도 양의 노이즈를 넣어 다시 재구성할 것인가
- 노이즈 값이 많음 : 원래 인풋이 뭉개져 예측 불가한 결과
- 노이즈 값이 적음 : 인풋과 유사한 결과
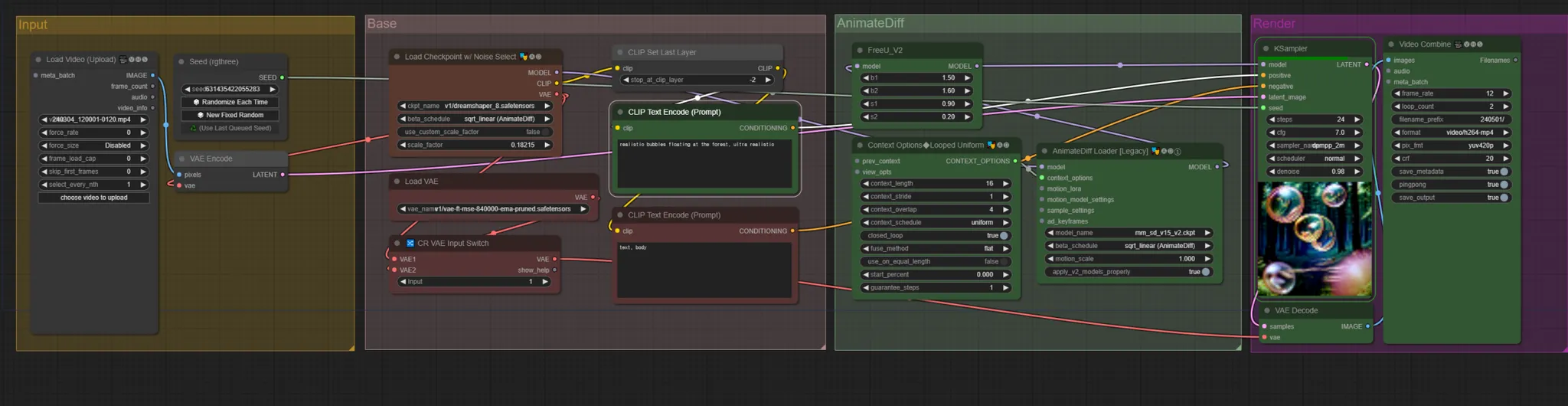
Video to Video 워크플로우
- Img to Img와 다르게 중간에 AnimateDiff라는 모션 모듈이 있음
- 블렌더에서 만든 모션그래픽을 인풋 삼아 AnimateDiff를 활용해 비디오를 추출할 예정
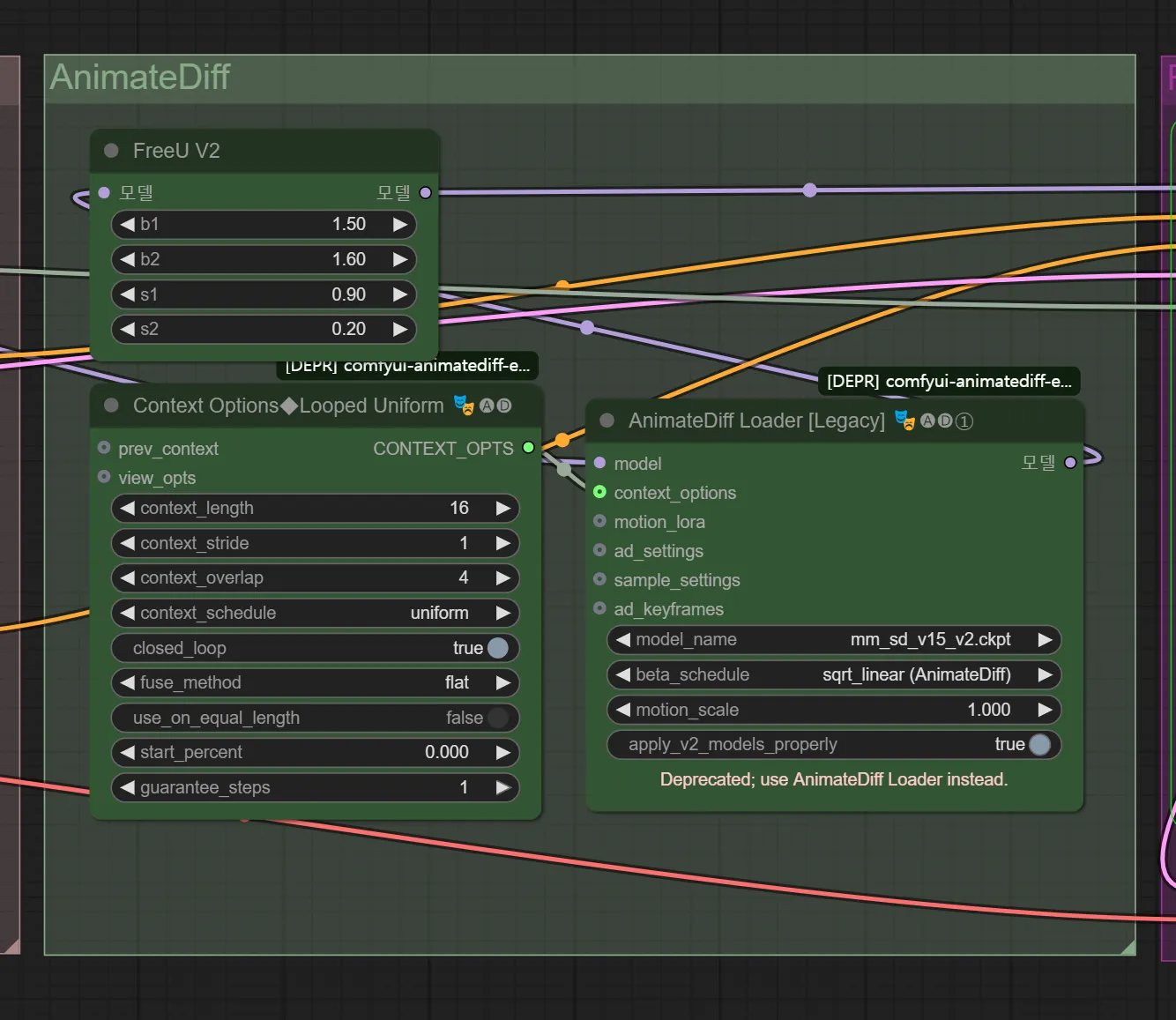
모델 파라미터 요소
AnimateDiff
- FreeU : 애니메이션을 만드는 데에 있어 일관성을 유지하도록 도와주는 값들. 현재 값들에서 크게 벗어나지 않는 것을 추천
- Context Option : 애니메이션을 만드는 데에 있어 일관성을 유지하는 것들에 대한 조정 값
- AnimateDiff Loader : 모션 모듈을 적용할 수 있음. 모션 모듈은 AnimateDiff를 위해 모션을 위한 체크포인트를 적용
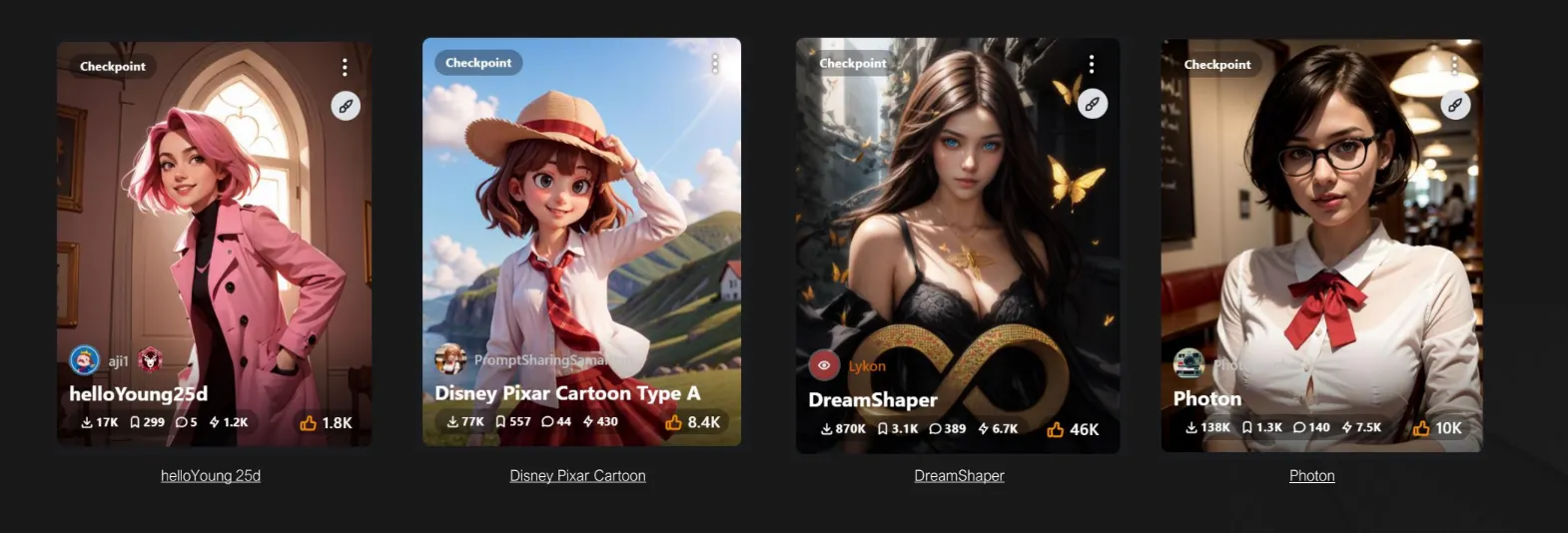
Checkpoint(.ckpt)
- 워크플로우에서 가장 중요한 역할
- 학습된 모델의 특정 상태를 저장한 파일로, 이를 통해 이미지 생성의 품질과 스타일을 유지할 수 있음
- 기존에 다운로드 받은 체크포인트 모델이 있다면 Data\Models\Stable Diffusion 폴더 내에 옮기기
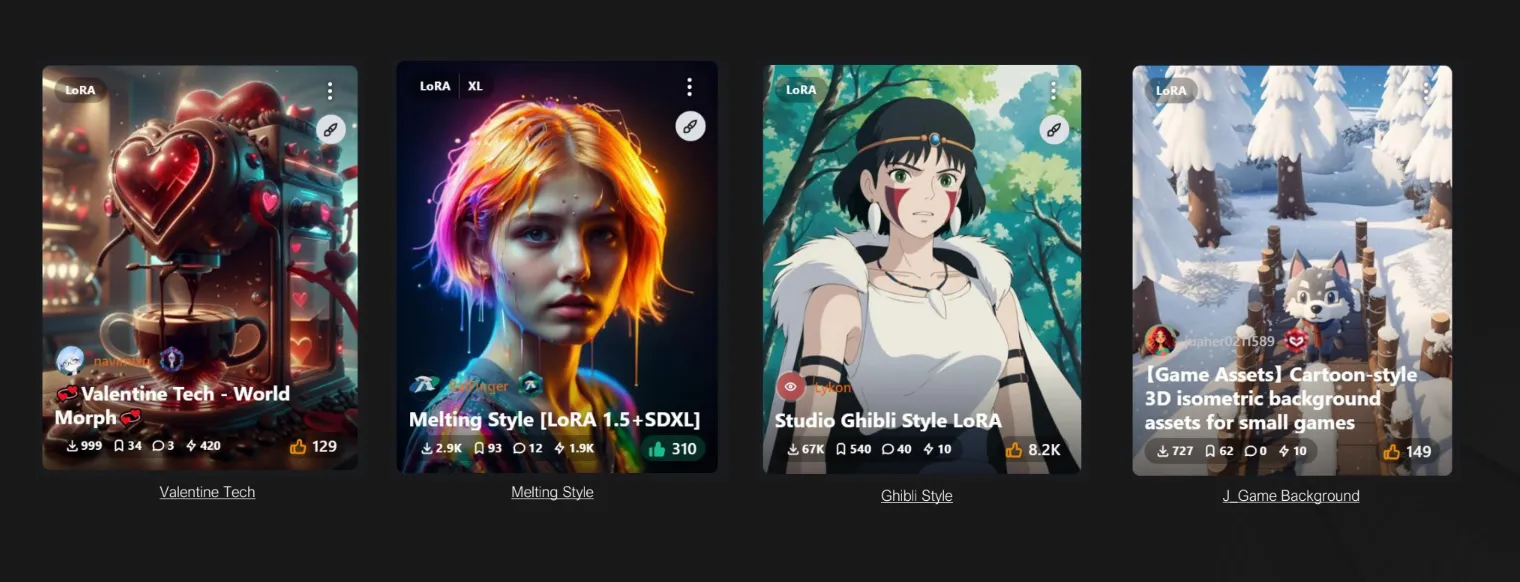
LoRA
- Checkpoint가 기본 성능을 제공한다면, LoRA는 특정한 기능이나 성능을 개선하는 데 도움을 주는 추가 장치
- 모델의 특정 부분만을 미세 조정해 효율적으로 학습할 수 있도록 돕는 기술로, 작은 데이터셋으로도 고품질의 결과를 얻을 수 있음(용량이 비교적 작음)
- Checkpoint의 모델 소켓에 LoRA 모델을 생성해 연결. Clip도 연결
- 기존에 다운로드 받은 Checkpoint 모델이 있다면 Data\Models\Lora 폴더 내에 옮기기
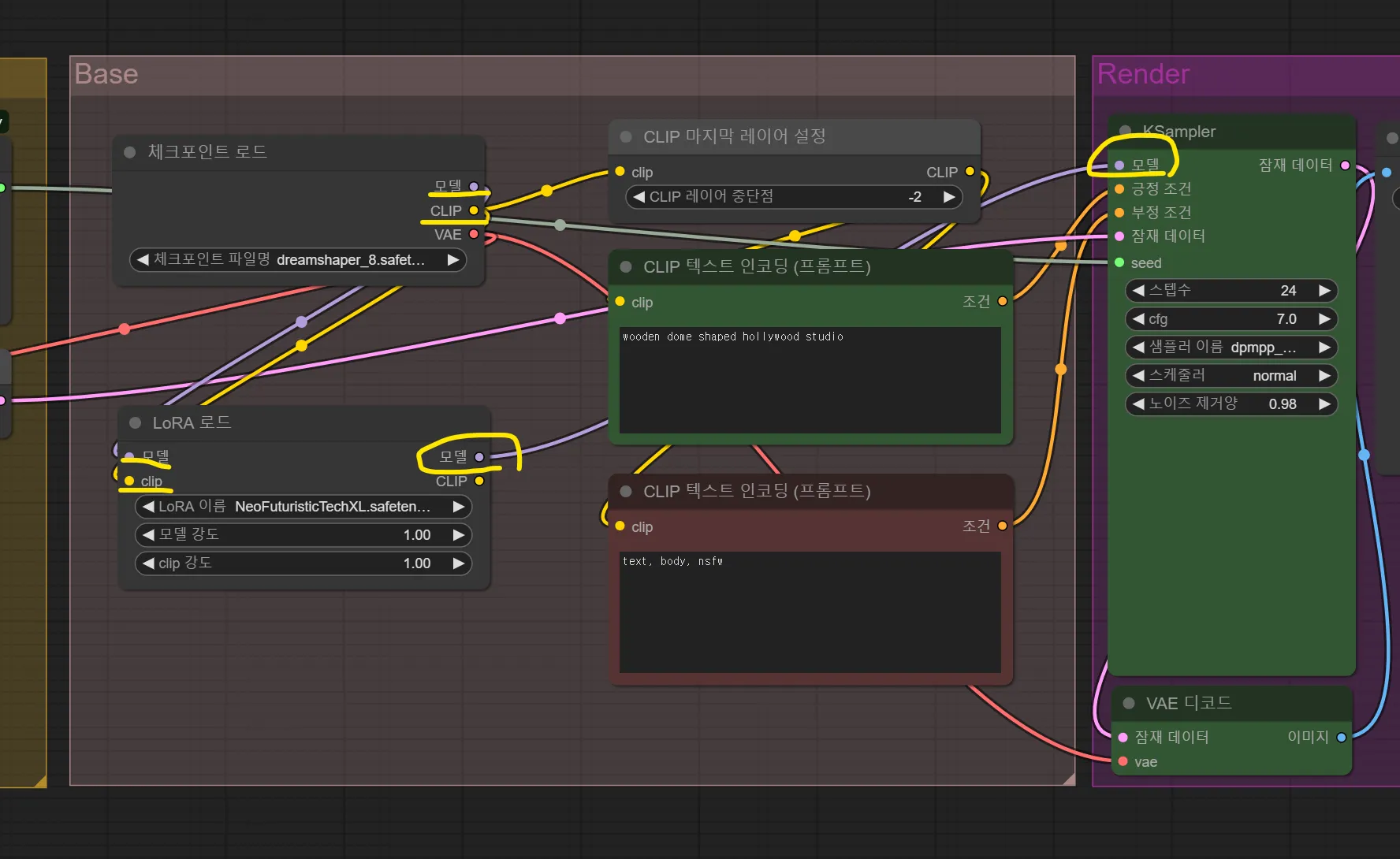
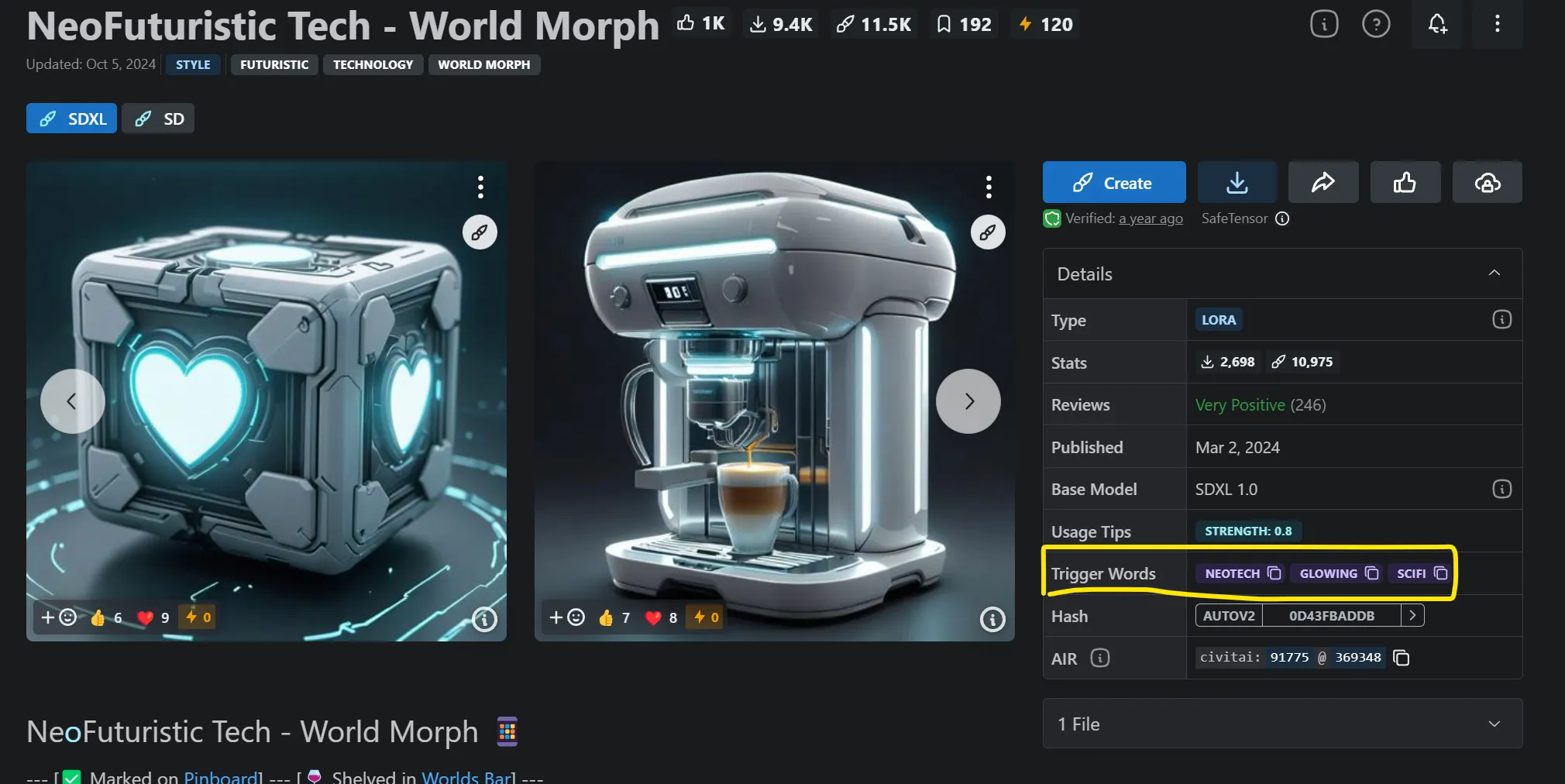
- 프롬프트에 꼭 LoRA를 트리거 할 단어들을 찾아서 프롬프트에 넣어주기

ControlNet
- 특정 조건의 알고리즘(테두리 선, 깊이감, 사람과 동물의 자세 등)에 따라 이미지에 대한 가중치를 보여하는 모델. 사용자가 원하는 형태나 스타일을 더 정말하게 반영할 수 있도록 도움
- 다양한 알고리즘에 따라 이미지 대한 해석을 다르게 함

- 네 가지의 ControlNet을 사용했다면 더 많은 양의 깊이감, 테두리, 소프트엣지, 라인에 대한 분석이 많이 들어가 제한점이 많음. 오른쪽은 깊이감만 ControlNet을 적용해 자유도가 높음
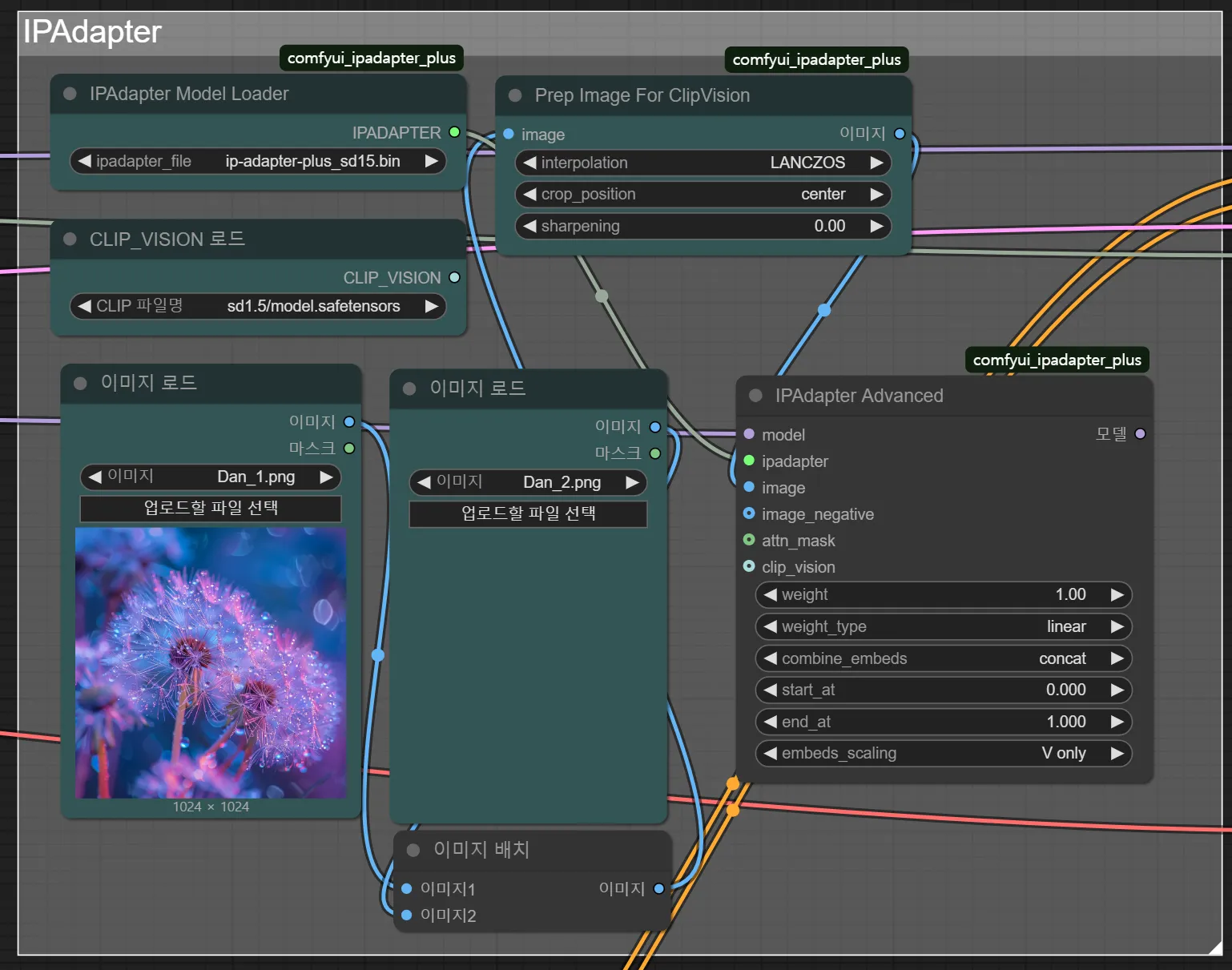
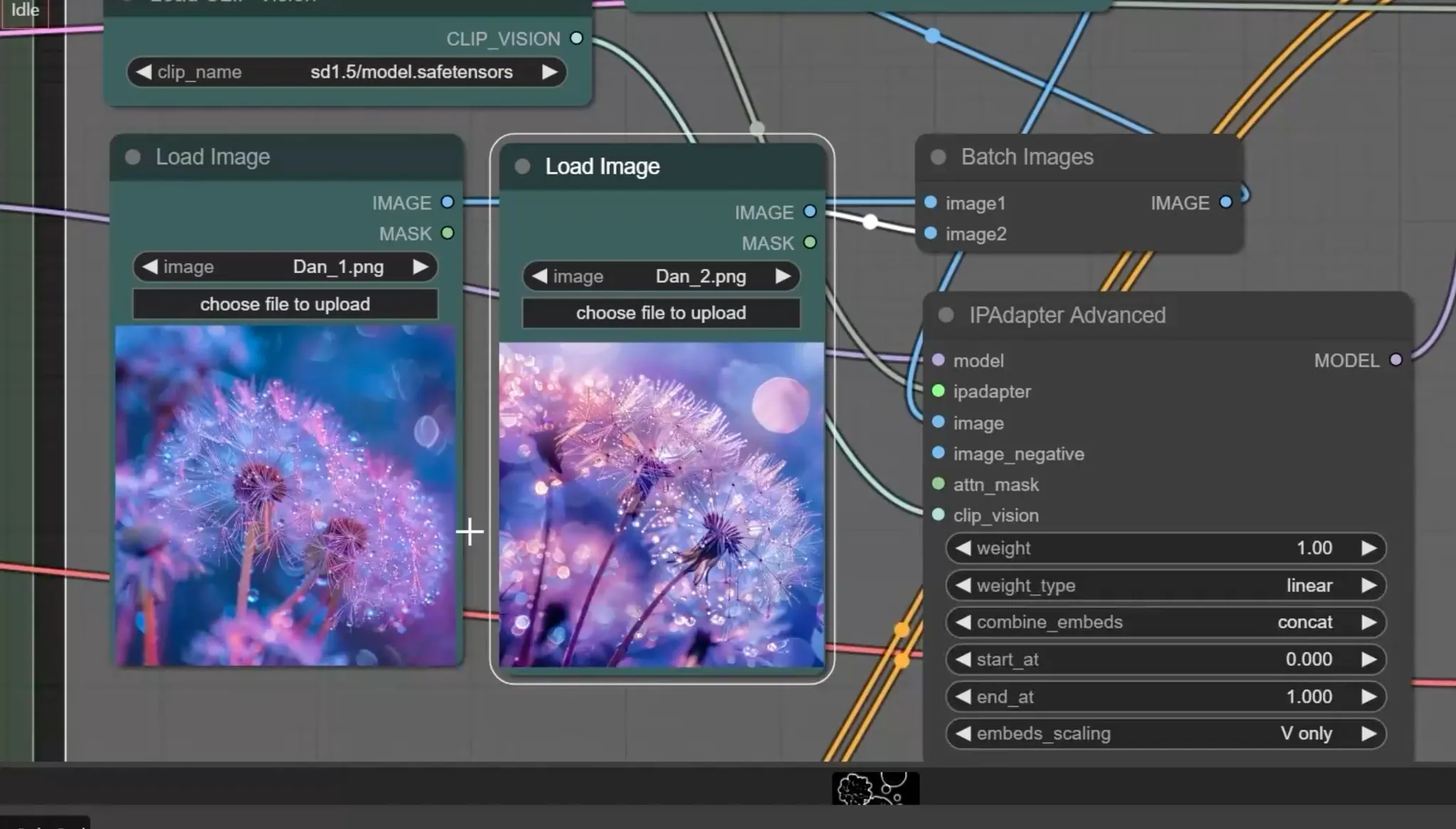
IP-Adapter
- Image Prompt - Adapter의 줄임말
- 이미지 그 자체가 프롬프트로써 작용한다는 것
- IP-Adapter Model과 이미지들을 해석해 줄 모델인 Clip Vision 모델도 다운로드 받아야 함

'2. 3D 렌더링 및 생성형 AI 공부 > Stable Diffusion & Blender' 카테고리의 다른 글
| 2. [Stable Diffusion] Blender & Stable Diffusion 활용 (1) | 2025.03.28 |
|---|